



 Branimir Valentic
Branimir Valentic The old saying “If you can’t measure it – you can’t manage it” is quite truthful. How can you know if you have to push the brake or if you have to speed up, if you don’t know your speed? IT is the same. If you don’t know where you are – you can’t direct your next step.
KPIs and CSFs
If you take a look at ITIL books, you will quite often find something that is called Key Performance Indicators (KPI) or Critical Success Factors (CSF). These two parameters define what will be measured. What is the difference? CSF describes what has to be achieved (if we want to say that something is successful) and KPI measures it (i.e. says if CSFs are achieved). For example, if CSF says that Service Desk efficiency has to be increased as part of a customer service improvement program, KPI would be to decrease the number of repeated incidents with known resolution by 50%. But, why do we measure? If we measure just for the sake of it – that’s useless and pointless. Measurement should be just a start of the next step; i.e. measurement should be a management tool to control, steer and guide toward achievement of defined goals. By measuring our processes, we gain the foundation to improve. Measurements consider efficiency of the processes (indirectly impacting business itself) and internal resources. Therefore, before we define measurement methods and parameters, we have to define critical processes and services which have a direct impact on business performance.
The metrics
By using metrics we quantitatively describe the process that is measured. Metrics define what should be measured. There are three types of metrics:
- Technology metrics – component and application metrics (e.g. performance, availability…)
- Process metrics – defined, i.e. measured by CSFs and KPIs
- Service metrics – measure of end-to-end service performance.
As we move downward on the list, measuring gets more complex. Technology is (relatively) easy to measure, CSFs and KPIs are more complex and end-to-end service measurements consist of many different components, processes and methodologies. When considering measurements it is crucial to define realistic, but challenging, measurement targets. As ITIL (Continual Service Improvement edition) describes, a good target is SMART:
- Specific
- Measurable
- Achievable
- Relevant, and
- Time-bound
ITIL references metrics and measurement in every phase of a Service Lifecycle. What is the practical usage? Who uses metrics? Simply – everyone. Customers want to know when their incident will be solved or how much they will have to pay for the service, the Service Desk and back office team need to know which incident they should solve first, and Management wants to know the efficiency of the processes and organization.
A few examples
IT service management tools already have many predefined parameters that are measured. I found that Management of such organizations uses tools and their measurements to control and direct. Here are two typical examples:
- Service Level Agreement (SLA) parameters are measured. They include Response Time, Repair Time and Resolution Time (Incident and Problem management). According to them, workload will be distributed inside the team, e.g. Incidents that require a shorter time to resolve will have higher priority than Incidents with longer resolution times.
- Monthly (or quarterly, yearly) report will show if SLA parameters are met. That means if Incidents were not resolved within the agreed time, penalties will apply. Such measurement can give valuable information: are SLA defined correctly, i.e. are we able to achieve agreed times? Do we have enough resources or technology (to measure)? Do they have the right skills? What is the utilization? …etc.
Efficient IT organizations use many measurements and their results. Therefore, they don’t experience many surprises or use unneeded resources (i.e. fewer panic situations); instead, they meet SLA and know who should do what.
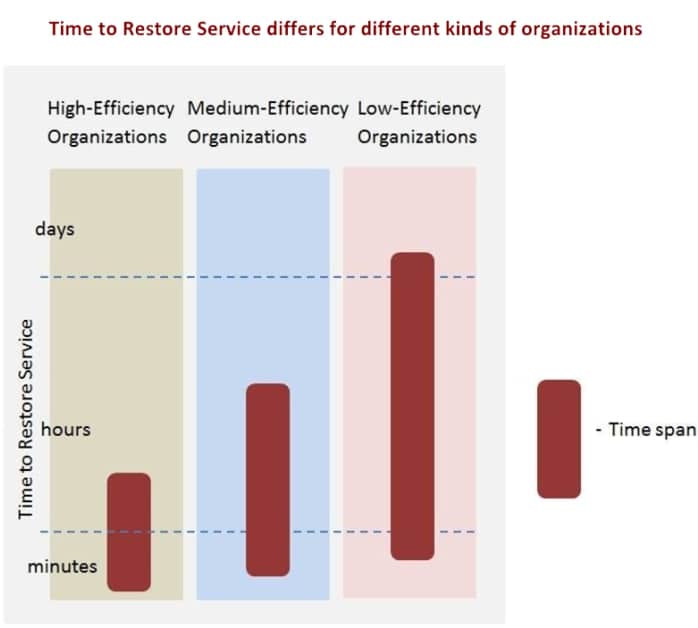
High-efficiency organizations need a few minutes up to a few hours to restore service. Low-efficiency organizations use much more resources and need much more time.
Low-efficiency organizations experience many “surprises,” redo the same incidents many times and don’t have control over processes and services; i.e. they always act reactively, rather than proactively, and require more time for the same job.
So, if you think that high performance by an IT organization is achieved by chance – I think you are wrong. High-performing organizations know what their (critical) processes are; they measure and improve. And, they achieve respective results.
Click here to see a free preview of the Continual Service Improvement Process template to learn more about service improvements.




