



 Branimir Valentic
Branimir Valentic Once your service is in the live environment, the Incident and Service Request Management process will count for the majority of your daily activities. This means, from a practical point of view, that your customers will judge you (as an IT service provider) based mostly (because there are a few more processes in this stage of the service lifecycle) on the efficiency of this process – this is because it is the most visible process in your user’s or customer’s eyes.
ISO 20000, like ITIL, has a very clear and quite extensive description of the requirements. ISO 20000 is different from ITIL in that it sets requirements for incident and service request handling in one process. Nevertheless, ITIL recommendations can be used in ISO 20000 implementation. What needs to be done is a filtering out of those ITIL recommendations that are not required by the standard, and adapting the rest to the company’s requirements.
One set of ISO 20000 requirements emphasizes the relationship of the Incident and Service Request Management process with some other processes in the scope of the SMS (Service Management System). I think that this is good, because it provides strong foundations for the efficiency of the process. Let’s see some more details.
The reasoning
It may sound simple – there is an incident, and you have to resolve it. It’s the same, or even easier, for service requests. But, the real world is more complex than that. Take, for example, an ongoing change. Another team (i.e., different from the people working on incident resolution) is deploying a change. Let’s say – an imperfect change implementation. A lot of new incidents are created based on the fact that the change that was recently implemented, or is still in implementation, contained errors. If the team who works on incident resolution knows what’s going on, they could immediately involve the people who implemented that change in order to react and prevent future incidents, and find resolution for existing ones.
Simply explained, Incident and Service Request Management has an important effect on live services, and it’s essential that people involved in the process can see the “big picture.” This means including all relevant information that can affect their work. Usually, that involves the inclusion of more information than that which is strictly incident, or service request, related.
What is it all about?
ISO 20000 is pretty direct when requiring that people involved in the Incident and Service Request Management process have access to all relevant information. So, according to the ISO 20000 requirements, people involved in Incident and Service Request Management must have access to:
- Known Errors (KE) – this is the knowledge management system of the company. Once you resolve incidents’ root cause (permanent fix) or find a workaround (temporary fix), you should document that information. Otherwise, you’ll need to start from scratch over and over again. Access to the Known Error Database (KEDB) will increase the speed of incident resolution. The KEDB can be in the form of a tool, a spreadsheet, or a document (a stand-alone text document or some note-taking application). The important thing is that incident and service request people can access it.
- Problem records – there are two points here I’d like you to know. The first is that incidents are (very often) triggers for problem tickets. The goal of the Problem Management process is to find the root cause of one or more incidents. This means that problems will say what caused an incident. Therefore, the people involved in incident management should have access to problem records. Secondly, Problem Management will fill the KEDB, and Incident and Service Request Management will use that knowledge to increase their efficiency.
- CMDB (Configuration Management Database) – as I explained in the article Knowing your herd – Service Asset and Configuration Management (SACM), there is a strong relationship between Incident and Service Request Management and Configuration Management (which is, according to ISO 20000, responsible for the CMDB). A well-managed CMDB increases incident resolution, incident and/or service request team efficiency, and, most importantly, customer satisfaction.
- Release and Deployment Management – releases can be sources of new incidents. Or, incidents can have an effect on upcoming releases. Therefore, information exchange is pretty important. This can be achieved by good management and communication between teams (see the articles IT Service Management communication according to ISO 20000 and Communication inside IT Service Management team – Setup of joint vocabulary and criteria to learn more about communication).
These are explicit standard requirements. But, from a practical point of view, there are some more interfaces that can contribute to the efficiency of the Incident and Service Request Management process. Here are a few examples:
- Change Management – as I mentioned, changes are often the cause of new incidents. Therefore, Incident and Service Request Management needs to know what (and when) changes are in implementation.
- Service Catalogue Management – the Service Catalogue is a list and description of services your customers see. If they, e.g., need to order something from the catalogue, the people who are handling service requests (what the customer has is actually a request) need to have the same information as the customer does.
- Information Security Management – security-related incidents are usually the most important ones. Therefore, the people who are handling incidents need to have an open communication channel with security management.
Basically, Incident and Service Request Management will build the above-mentioned interfaces using ITSM tools. The efficiency of such interface depends on how good your ITSM tool is.
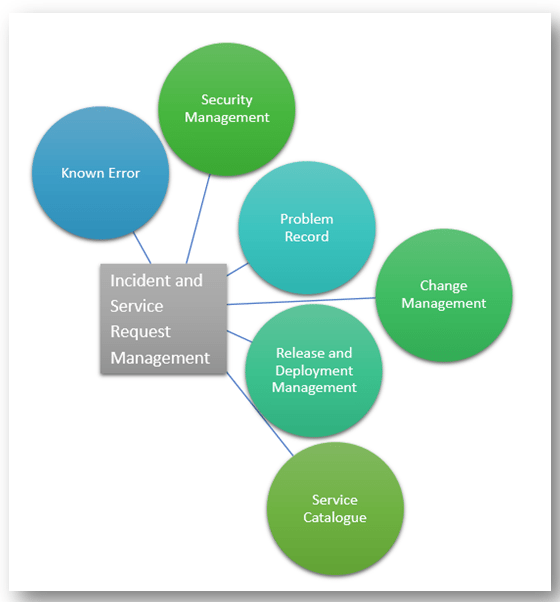 Figure: Interfaces of the Incident and Service Request Management process
Figure: Interfaces of the Incident and Service Request Management process
The benefits
The customer is the one who will judge the efficiency of your organization (as their IT service provider). But, they don’t see your developers, network admins, etc. What they see is your frontline, i.e., the people involved in the Incident and Service Request Management process. It is according to their efficiency that the whole organization will be evaluated.
So, in order to keep your customers happy (and, indirectly – your management, too), but also to simplify your own staff’s daily work, efficient Incident and Service Request Management is crucial. Interfaces to other processes are not only a must, but they are also your chance to excel, both internally as well as externally.
Use this free ISO 20000 Gap Analysis tool to check the fulfillment of your Incident and Service Request Management process.




