



 Drago Topalovic
Drago Topalovic The first task of a Service Desk is “Logging all relevant incident/service request details, allocating categorization and prioritization codes.” (ITIL Service Operation: Service Desk objectives)
Why is it so important?
A Service Desk needs to capture ticket data in order to enable proper staff allocation, to improve/enable Problem Management, to empower Management to create better decisions and to help build a useful Knowledge Database.
Priority
ITIL says that Priority should be a product of the Impact/Urgency matrix. ISO/IEC 20000 agrees with that in 8.1 Incident and service request management.
It is customary that Priority has four to five levels, and is marked with the numbers 1-4 or 1-5, where “1” is the highest and “5” is the lowest priority. It can also be marked by letters ABCD or ABCDE, with A being the highest priority.
The most commonly used priority matrix looks like this:
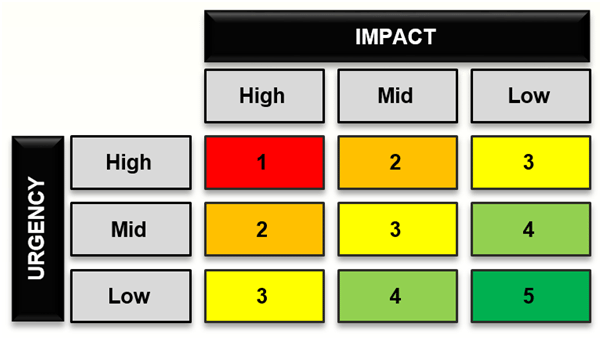
Impact – how critical the downtime is for the business. Usually, it is measured by the number of influenced users. If one or more services are down, the number can be determined from CMDB data or the service catalog.
Urgency – it is usually defined in SLA for the specific IT service. If more than one service is impacted, parameters for the higher urgency service will be taken into account.
 Example of resolution times regarding Incident Priority
Example of resolution times regarding Incident Priority
Should a customer have a say in determining the priority? Generally, no. If the SLA parameters are well-defined, this should be a straightforward job for the Service Desk. Two kinds of customers who usually add noise to this equation are:
- End users who overestimate the importance of their problem in the big scheme of things: they should be reassured that their ticket will be taken care on a best-effort basis according to their Service Level Agreement.
- VIP customer users trying to raise the priority of their tickets out of reasons not covered in their SLA. If there are available resources, good practice is to accept their request and deal with the ticket with requested priority, and mention the issue during the next SLA periodic meeting.
Changing priority during the incident lifecycle should be avoided, since most ITSM tools have problems recalculating escalation times and SLA parameters. This is especially true with lowering priority. An example would be lowering incident priority from 1 to 4 after the service restoration, in order to monitor the infrastructure and perform root cause analysis. Good practice here would be to resolve the ticket immediately after restoration, and to open a related Problem ticket. This way, the agreed Service Level is more easily monitored and reporting problems are avoided.
Categories
Why do we categorize? The main reasons are input for the Problem Management process and empowering decisions in Supplier Management. ITIL is not very specific in incident categorization. ISO20k, even less so.
Mostly, one has to rely on his ticketing tool abilities and customize them to his business requirements. Some tools I have seen living in upper Gartner quadrants are more rigid with regard to customization. They are multi-level in three to four layers. This should be enough for creating a useful category tree, though.
Depending on the scope of the organization’s service management, here are a few examples of category trees:
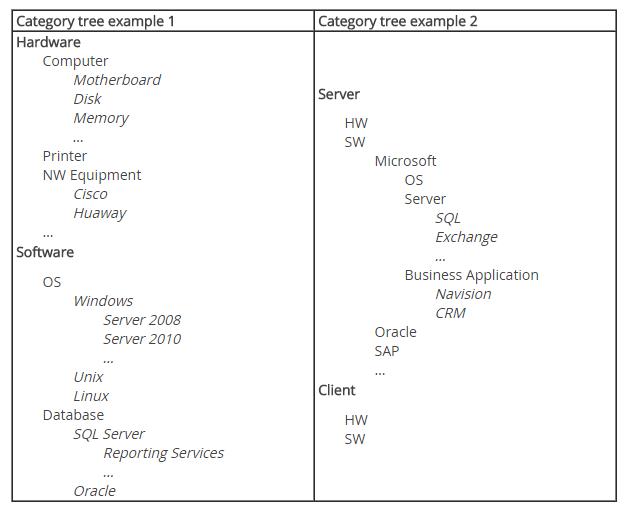
The depth of the category tree should be revised periodically and changed according to organization needs. I know some clients with five and six category layers where more than three layers are seldom used, but the tree is not maintained. So when a new technology ticket is raised it takes the category “Misc.” A good idea is to open a category “Old” and to put all the obsolete technology there. This way, database integrity is intact and it doesn’t influence reporting.
Some industry flagship tools enforce fixed layers like: Category:Subcategory:ProductType:ProblemType, or Category:Type:Item. These are good technical schemas and good meaningful categorization can be fit into them, even for less-then-technical business customers.
I have seen serious ticketing applications which incorporate a service into categorization. I feel strongly negative about this. One or more impacted services should be indicated when the affected Configuration Item is selected. If a network segment or a server is down, info from Service Catalog or at least Configuration Management Database relations should indicate which services are impacted, and downtime recording for each one of them should be started for SLA metrics. When impacted services are selected this way, an Assignment group or engineer Queue for the service will be automatically selected.
And another thing, the initial category can often be inaccurate, due to an initial lack of data. So the tool should enable the category to change during the lifecycle of the ticket.
Resolution codes
There is another type of ticket category, dealing with ticket resolution. Resolving the ticket can be categorized by a small, meaningful number of categories, or an elaborate category tree for the more demanding analytics/reporting.
Usually there are indicators of Successful resolution (helps with ISO 20000 requirements, thank you), and beside it an “Unsuccessful” code, of course; then you need a code for “Out of Scope,” and a “Problem by Design” code, meaning “It’s not a bug, it’s a feature.” And you are set to go. If built rationally, this group of categories rarely requires revisions.
Categorizing and prioritizing are the basic Service Desk tasks, so adequate attention is required during the implementation and maintenance of the Service Desk application, as well as on proper staff education.
I would appreciate if readers would leave some feedback, if possible. Example: after reading this post, how do you feel the ticket for mail client malfunction on a Marketing Manager notebook in your company should be prioritized and categorized?
Download a free preview template of Incident Management process to get an overview of activities, roles, and responsibilities needed for incident categorization.




